Introduction
If you don’t know EXPLAIN and are starting with this article, I really encourage you to start from the beginning, to understand better what a query plan is and how to use EXPLAIN. The previous article covers that.
In this article, I’m going to try to clarify the different types of scans used to filter tables and retrieve the exptected rows.
I’m here taking the example of a letter delivery system. Owls deliver letters between humans. Here is the data model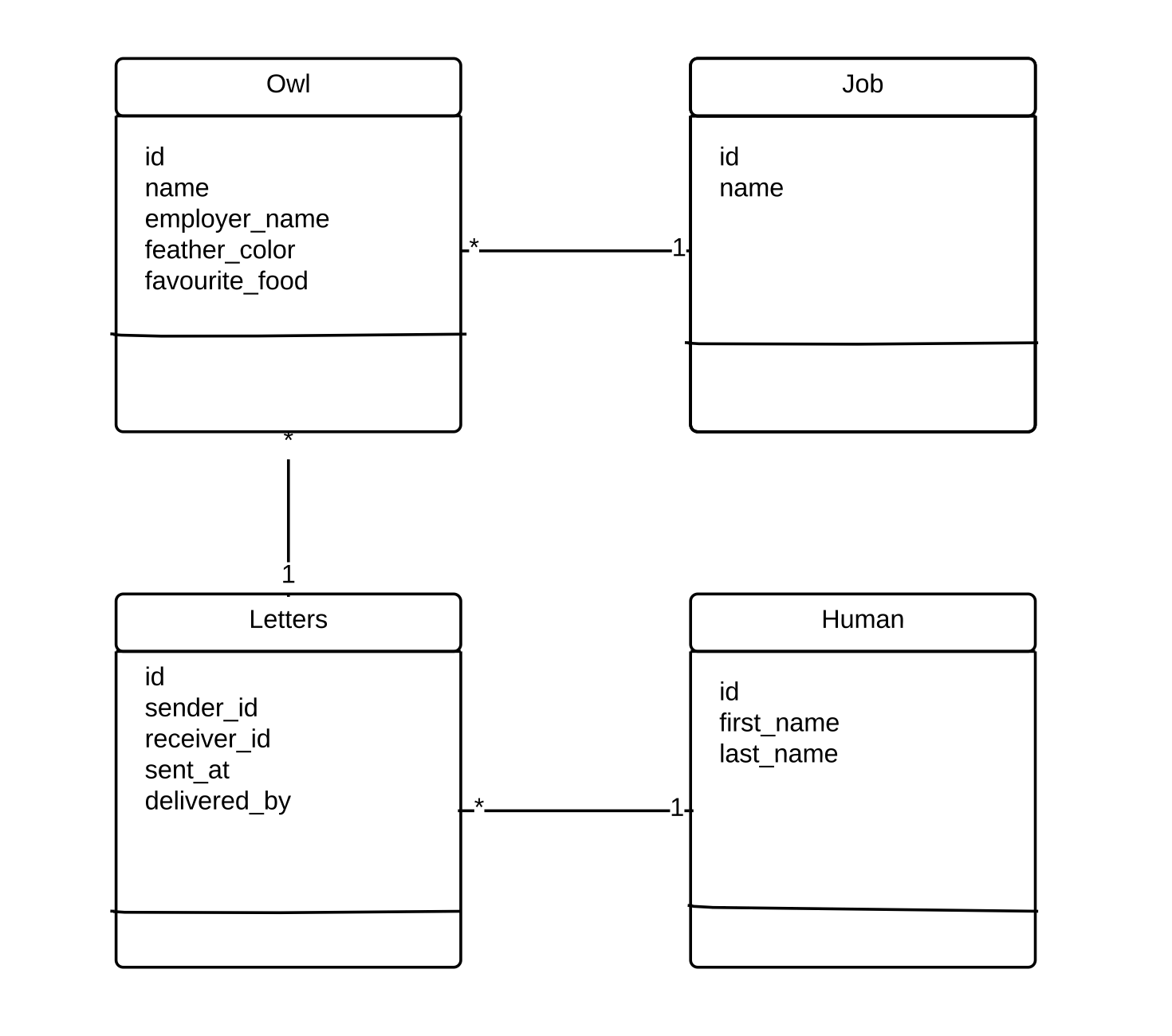
In this tables I have:
- 10 002 Owls
- 10 000 Humans
- 413861 Letters
- 7 Jobs
You can find a dump of this DB here.
Sequential scan
In the previous article we where analyzing the result of this EXPLAIN
owl_conference=# EXPLAIN ANALYZE SELECT * FROM owl
WHERE owl.employer_name = 'Ulule';
QUERY PLAN
------------------------------------------------------------
Seq Scan on owl (cost=0.00..205.03 rows=1 width=35)
(actual time=1.904..1.904 rows=1 loops=1)
Filter: ((employer_name)::text = 'Ulule'::text)
Rows Removed by Filter: 10001
Planning time: 0.251 ms
Execution time: 1.956 ms
(5 rows)
You can see a seq scan. The sequential scan simply scans the entire table and retrieves the rows matching the where clause.
It’s much like reading an entire encyclopaedia to get the information you need. You understand how it can be expensive for a big table.
You might need an index.
Index scan
Let’s try on to add an index on the column employer_name used in our previous query.
CREATE INDEX ON owl (employer_name);
After creating the index, if we run the same query, it suddenly starts using the index
EXPLAIN ANALYZE SELECT * FROM owl WHERE employer_name='Ulule';
QUERY PLAN
-------------------------------------------------------------------------------------------
Index Scan using owl_employer_name_idx on owl (cost=0.29..8.30 rows=1 width=35)
(actual time=2.399..2.400 rows=1 loops=1)
Index Cond: ((employer_name)::text = 'Ulule'::text)
Planning time: 0.111 ms
Execution time: 0.065 ms
An Index Scan explores the B-Tree and walks through the leaves to retrieve the matching rows.
Index Scan or Sequential scan ?
 If I try this query
If I try this query
owl_conference=# EXPLAIN SELECT * FROM owl
WHERE employer_name = 'post office';
QUERY PLAN
---------------------------------------------------------
Seq Scan on owl (cost=0.00..205.03 rows=7001 width=35)
Filter: ((employer_name)::text = 'post office'::text)
(2 rows)
The explain shows that it is using a sequential scan, and retrieving 7000 rows. As there is an index, it might seem weird to you.
In a sequential scan, the reading head reads in memory order, so it only has to go to the next memory block to scan the tables. In the case of an index it has to “jump” between the pointers given by the tuples (value, pointer) in the index.
Moving the reading head is 1000 slower than reading the next physical block. When you read a book, reading the next page is easier for you than jumping to the page 34, then 98, then 12… It’s the same for the reading head :)
So if a value is common in your table, it’s quicker to simply read everything.
Bitmap heap scan
I have 2000 owls working at Hogwarts (it’s a pretty big employer, not as big as the post office, but still).
Let’s look at the result of the EXPLAIN
owl_conference=# EXPLAIN ANALYZE SELECT * FROM owl
WHERE owl.employer_name = 'Hogwarts';
QUERY PLAN
-------------------------------------------------------------------------------------------------
Bitmap Heap Scan on owl (cost=47.78..152.78 rows=2000 width=35)
(actual time=12.424..17.496 rows=2000 loops=1)
Recheck Cond: ((employer_name)::text = 'Hogwarts'::text)
Heap Blocks: exact=79
-> Bitmap Index Scan on owl_employer_name_idx (cost=0.00..47.28 rows=2000 width=0)
(actual time=12.331..12.331 rows=2000 loops=1)
Index Cond: ((employer_name)::text = 'Hogwarts'::text)
Planning time: 0.117 ms
Execution time: 17.702 ms
(7 rows)
It’s using something called a Bitmap Heap Scan.
In this algorithm, the tuple-pointer from index are ordered by physical memory into a map. The goal is to limit the “jumps” of the reading head between rows. When you think about it, a encyclopaedia’s index is close from the structure of this map. For the word that you are looking for, the pages are ordered.
But here you can see Recheck Cond: ((employer_name)::text = 'Hogwarts'::text).
If there are too many rows, the bitmap then contains the pages where the rows are. Then this pages are scanned, physical block after another, and the condition is rechecked.
It would be like having in your encyclopaedia the list of chapters where you can find what a pretty common word instead of a very long list of pages. You would then read the chapters and perform your own recheck condition by just ignoring the information you’re not interested in.
Conclusion
 So there are three types of scans:
So there are three types of scans:
- The sequential Scan
- The Index Scan
- The Bitmap Heap Scan
Now the next article will cover the joins.